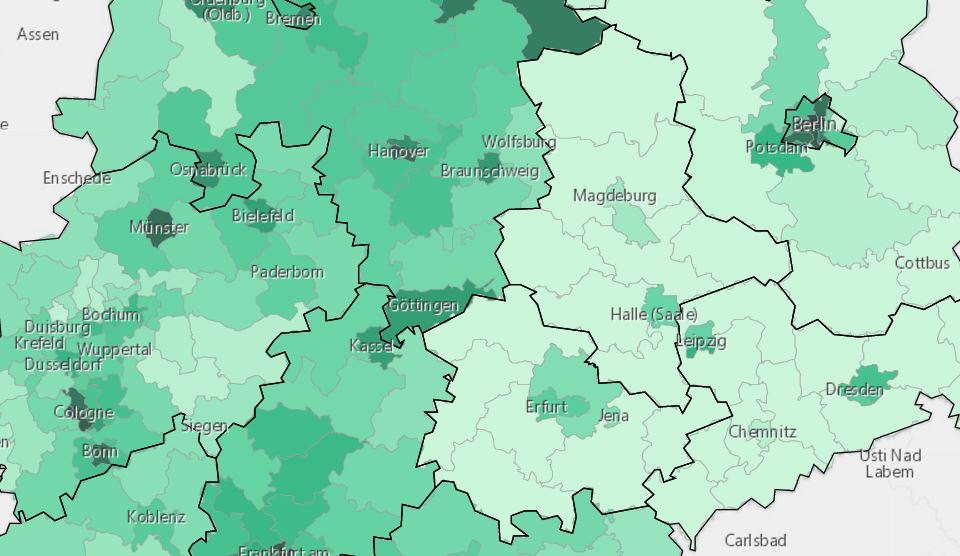
Über die Ergebnisse der Bundestagswahl 2017 wurde heiß diskutiert. Dabei ging es nicht nur darum, welche Parteien insgesamt besonders stark oder schwach abgeschnitten hatten. Auch der Raum spielte eine entscheidende Rolle, da sich die Wahlergebnisse räumlich stark unterschieden haben – hier seien starke Ost-West-Gegensätze als Beispiel genannt.
Uns hat interessiert, inwiefern sich die räumlichen Unterschiede in den Stimmenanteilen für die sechs größten Parteien mit ArcGIS und der Spatial Statistics Toolbox analysieren lassen. Die Ergebnisse finden sich in dieser Storymap.
In diesem Blogpost möchte ich mit einer kurzen Anleitung jeden, der sich für die Analyse von Wahlergebnissen mit GIS und Statistik interessiert, animieren, ähnlich vorzugehen:
1. Schritt: Darstellen, was man erklären möchte
In meiner Analyse wollte ich primär die Wahlergebnisse in Form von Zweitstimmenanteilen pro Wahlkreis erklären. Dazu brauchte ich zuerst die Wahlergebnisse und die Geometrien der Wahlkreise. Beides gibt es auf ArcGIS Online als Feature Layer. Diesen Layer kann ich je nach Belieben in ArcGIS Online, ArcGIS Desktop oder in Excel als Tabelle öffnen, kopieren und eine neue Spalte mit prozentualen Anteilen für die Zweitstimmen berechnen.
Es ist hilfreich, dann Webkarten für jede der sechs Parteien zu erstellen, die den Zweitstimmenanteil pro Partei mit unterschiedlichen Farbintensitäten darstellen.
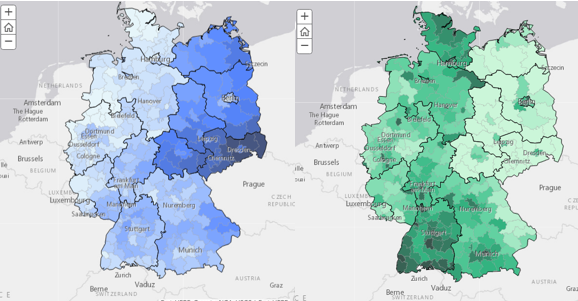
2.Schritt: Überlegen, wie man es erklären möchte
Es wurde in den Medien viel spekuliert, wie die Wahlergebnisse mit Stadt-Land-Gegensätzen, Bildungsniveau, Religion, Ausländeranteil, Arbeitslosenquote, Wohlstand oder Altersstruktur zusammenhängen könnten. Ich wollte mehrere verschiedene Variablen untersuchen, um ihren Zusammenhang mit Wahlergebnissen zu untersuchen.
Zunächst haben wir uns an die Geomarketing-Experten von Nexiga gewandt und verschiedene Variablen auf Wahlkreisebene erhalten. Ich habe mich auf sieben dieser Variablen fokussiert. Außerdem stellte ich erfreut fest, dass auf der Website des Bundeswahlleiters einige Strukturdaten zur Verfügung stehen, die ebenfalls als erklärende Variablen dienen könnten. Diese Daten sind mittlerweile auch auf ArcGIS Online als Feature Layer.
So hatte ich in der Summe bereits 15 mögliche erklärende Variablen für die Analyse.
In ArcGIS habe ich über einen einfachen Table Join nun meine Wahlergebnisse (1. Schritt) mit den Nexiga- und Bundeswahlleiter-Daten verbunden und hatte einen Datensatz (Feature Class) mit allen Variablen, den ich für die Arbeit mit der Spatial Statistics Toolbox (siehe 3. Schritt) verwenden konnte.
Bevor ich die statistischen Analysen durchführte, habe ich für jede erklärende Variable wieder eine Karte erstellt und bereits so erstaunliche Zusammenhänge zwischen Wahlergebnissen und meinen soziodemografischen Variablen festgestellt.
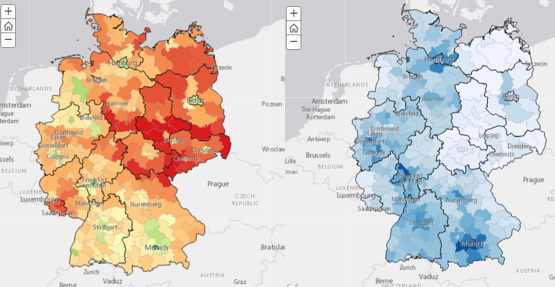
Wer wissenschaftliche Hypothesen über statistische Zusammenhänge aufstellen möchte, hat allein durch diese Karten und den visuellen Vergleich zwischen zu erklärenden (Wahlergebnisse) und erklärenden Variablen (soziodemografische Faktoren) schon eine große Hilfestellung.
3. Schritt: Berechnen statistischer Zusammenhänge mit OLS
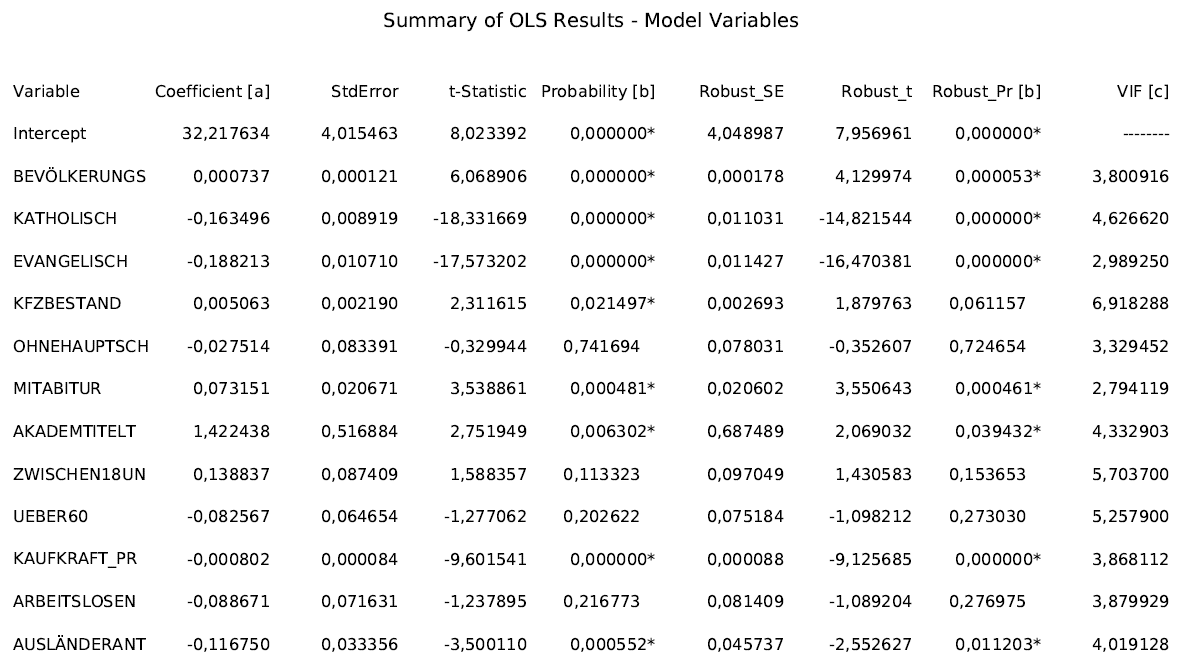
Nun hatte ich Karten für die Wahlergebnisse und für die erklärenden Variablen. Aber ich wusste noch nichts über die Stärke der statistischen Zusammenhänge. Zur Bewertung dient das Werkzeug Ordinary Least Squares in der Spatial Statistics Toolbox. Es ist bereits in ArcGIS Desktop Basic enthalten.
Damit erhalte ich einen umfangreichen Report und für jede Partei eine Karte mit roten und blauen Wahlkreisen.
In diesem Report im PDF-Format erhalte ich zunächst alle relevanten statistischen Maßzahlen, die die folgenden Fragen beantworten können:
- Ist der Zusammenhang zwischen erklärender und zu erklärender Variable positiv oder negativ? (Koeffizient > oder < 0)?
- Sind die Zusammenhänge relevant (Robust_Pr < 0,05)?
- Wie gut schätzt mein Modell das Ergebnis der jeweiligen Partei (R-Squared möglichst hoch)?
- Sagen meine erklärenden Variablen wirklich alle etwas Anderes aus oder muss ich – wie in meinem Fall (Geburtensaldo und Über-60-jährige) – einige Variablen streichen (VIF > 7,5), um Multikollinearität zu vermeiden?
Mehr dazu in diesem Tutorial oder der ArcGIS Hilfe.
Die Karten mit roten und blauen Wahlkreisen sind nun wie folgt zu verstehen: Wäre mein Modell aus Schritt 2 mit allen erklärenden Variablen perfekt, gäbe es keine roten und blauen Wahlkreise und keine sogenannten Residuen. Aber jedes statistische Modell erklärt Wahlergebnisse nur teilweise und mit einer gewissen Unsicherheit, denn es handelt sich ja nicht um „Naturgesetze“.
In roten Wahlkreisen unterschätzt das Modell die Wahlergebnisse für die jeweilige Partei, in blauen Wahlkreisen überschätzt es sie signifikant. In anderen Worten, in roten Wahlkreisen ist die Partei stärker als es die erklärenden Variablen vermuten lassen, in blauen ist sie schwächer.
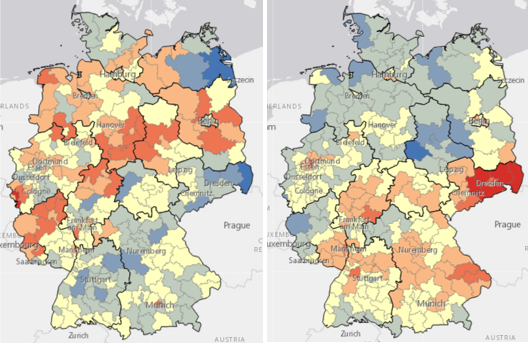
Es sei grundsätzlich gesagt, dass ein gewisses Grundwissen in Teststatistik für die Analyse von OLS-Ergebnissen unabdingbar ist, um die Aussagekraft der Ergebnisse einschätzen zu können. Auch über die Relevanz von p-Werten und R-Squared finden sich zahlreiche wissenschaftliche Artikel. Im Rahmen dieses Blogposts kann es nur ums grundsätzliche Prinzip gehen.
4. Schritt: Räumliche Autokorrelation und GWR
Meine Residuen sind räumlich stark geclustert: Gewisse Parteien werden in einigen Bundesländern komplett unterschätzt, andere Parteien in anderen Bundesländern komplett überschätzt. Der Test auf räumliche Autokorrelation sagt aus, dass die räumliche Verteilung der Über- und Unterschätzung nicht zufällig ist (p < 0,001 für alle sechs Parteien).
Um die Modellvoraussetzungen für GWR (Geographically Weighted Regression) zu erfüllen, musste ich für jede Partei rund die Hälfte der Variablen entfernen, damit die Modellvoraussetzungen gegeben sind. Daher haben sich in meinem Fall die Voraussageergebnisse durch GWR gegenüber OLS nicht signifikant verbessert und ich gehe an dieser Stelle nicht weiter auf die Ergebnisse ein.
5. Schritt: Aufbereiten und kommunizieren
Mit Esri Storymaps lassen sich räumliche Analysen leicht ansprechend aufbereiten. Gerade weil ich mit sehr vielen verschiedenen Webkarten gearbeitet habe, waren für mich die Story Map Series Templates sehr hilfreich.
Da die textliche Beschreibung der Analyse für meine Gesamtstory einen gewissen Raum einnimmt, habe ich mich für den „Klassiker“ Map Journal entschieden, um die einzelnen Story Map Series Templates miteinander zu verbinden.
Letztlich habe ich eine Anwendung erhalten, die ich selber jederzeit mit den Ideen von Kollegen und Lesern (vielen Dank dafür!) in Form von Karten, Text und Grafiken verändern und erweitern sowie überall im Webbrowser zeigen und mehr oder weniger kontrovers diskutieren kann.
Fazit
Wer sich nicht nur für die Darstellung von Wahlergebnissen, sondern auch für die Erklärungsfaktoren dahinter interessiert, hat mit den Spatial Statistics Tools in ArcGIS einen mächtigen Werkzeugkasten. Was mir persönlich gut gefällt, ist, dass nicht nur ein kartografisches Ergebnis, sondern auch umfangreiche Reports entstehen, die alles enthalten, was Statistikinteressierte brauchen. Die Werkzeuge sind auch für Einsteiger gut dokumentiert. Allerdings ist ein solides statistisches Grundwissen trotzdem sehr hilfreich für die Interpretation.
Jan Wilkening
Solution Engineer Education and Science









